AI Infrastructure Reaches Layer Four: How Gate.AI Builds the Model Routing Layer
The AI industry in 2026 is undergoing a profound paradigm shift. The conversation has moved from "Which model is best?" to "How can multiple models work together?" According to industry data, global AI spending is projected to reach $2.59 trillion in 2026, up 47% year-over-year. Of this, AI infrastructure spending will jump from $975.58 billion to $1.43 trillion. Combined capital expenditure on AI infrastructure by global tech companies will exceed $600 billion.
Amid this wave of infrastructure expansion, a previously overlooked layer is coming to the forefront—the model routing layer. This layer is distinct from both the model training layer and the inference service layer. Instead, it stands as the fourth independent layer within the AI infrastructure stack, serving as a critical bridge between upper-layer applications and underlying model resources.

From Three Layers to Four: The Evolution of the AI Infrastructure Stack
Traditionally, AI infrastructure has been divided into three layers: the compute layer (GPU clusters and computational resources), the storage layer (training data and model weights), and the model service layer (model training, fine-tuning, and inference deployment). This architecture worked well in an era dominated by single models—enterprises could simply connect to APIs from OpenAI or Anthropic to handle most AI tasks.
However, the market landscape in 2026 is fundamentally different. No single model can maintain absolute leadership across all tasks. Running five or more models in production environments has become the norm. The challenge for enterprises is no longer "Which model should we choose?" but "How can we make multiple models work together within a unified architecture?"
This shift has given rise to the fourth layer of AI infrastructure—the model routing layer. Situated between applications and model providers, this layer handles unified access, intelligent scheduling, cost management, and data privacy protection. The model routing layer is not a new large language model; rather, it is a unified access platform that sits between the application layer and model providers.
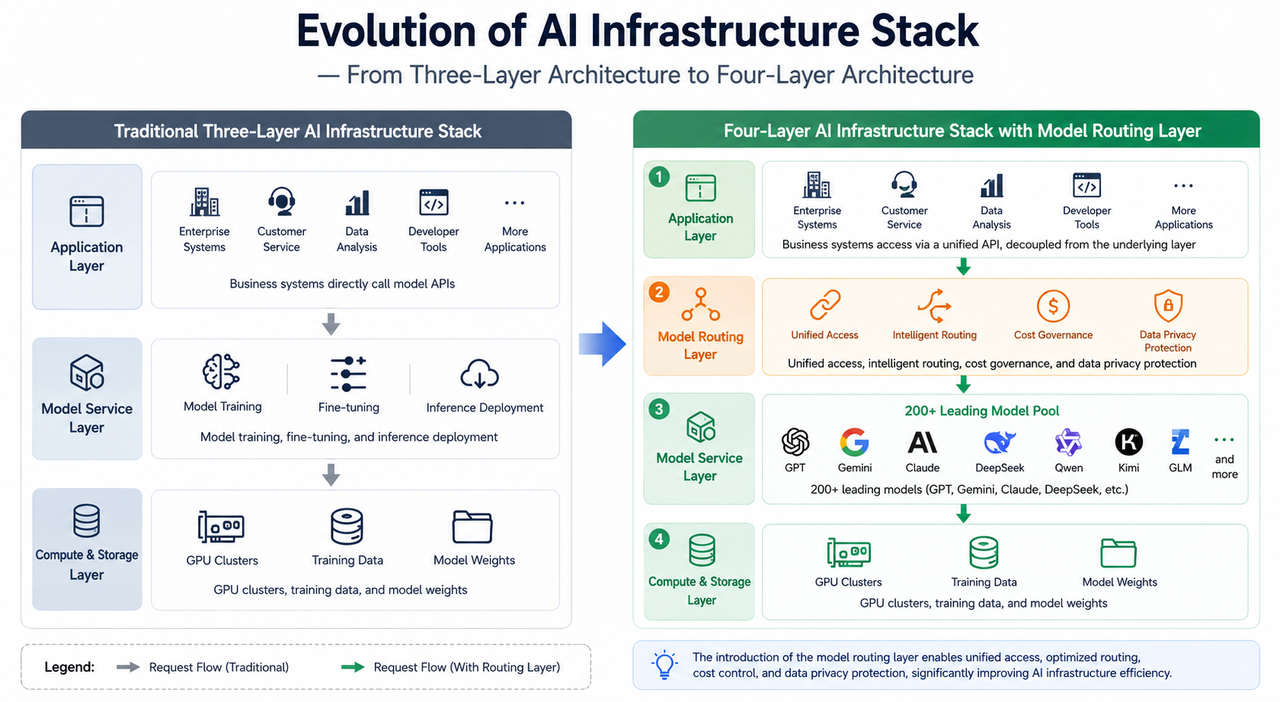
Comparing the evolution of the AI infrastructure stack—from a three-layer to a four-layer architecture
The Model Routing Layer: Definition and Core Value
The model routing layer is the intelligent intermediary within the AI infrastructure stack that assigns application requests to the most suitable model. For each request, it evaluates task characteristics, dynamically selects the optimal model, and forwards the request accordingly.
This layer is fundamentally different from a traditional API gateway. While a standard API gateway excels at managing request traffic, performing authentication, and rate limiting, the model routing layer must understand the content of each request—task complexity, required inference capabilities, latency requirements, and cost constraints—and make routing decisions based on these signals. In simple terms, an API gateway decides "Should this request be allowed through?" whereas the model routing layer decides "Which model should handle this request?"
The core value of the model routing layer is threefold:
First, decoupling. Business logic no longer directly depends on any specific model provider’s API. When onboarding a new model, configuration only needs to happen at the routing layer, with no changes required in the application layer.
Second, optimization. Lightweight tasks are assigned to cost-effective models, while complex inference tasks go to high-performance models. In practice, intelligent routing can reduce costs by up to 80% in certain scenarios.
Third, governance. The routing layer provides unified metrics for call volume, latency, failure rates, and costs, enabling end-to-end observability.
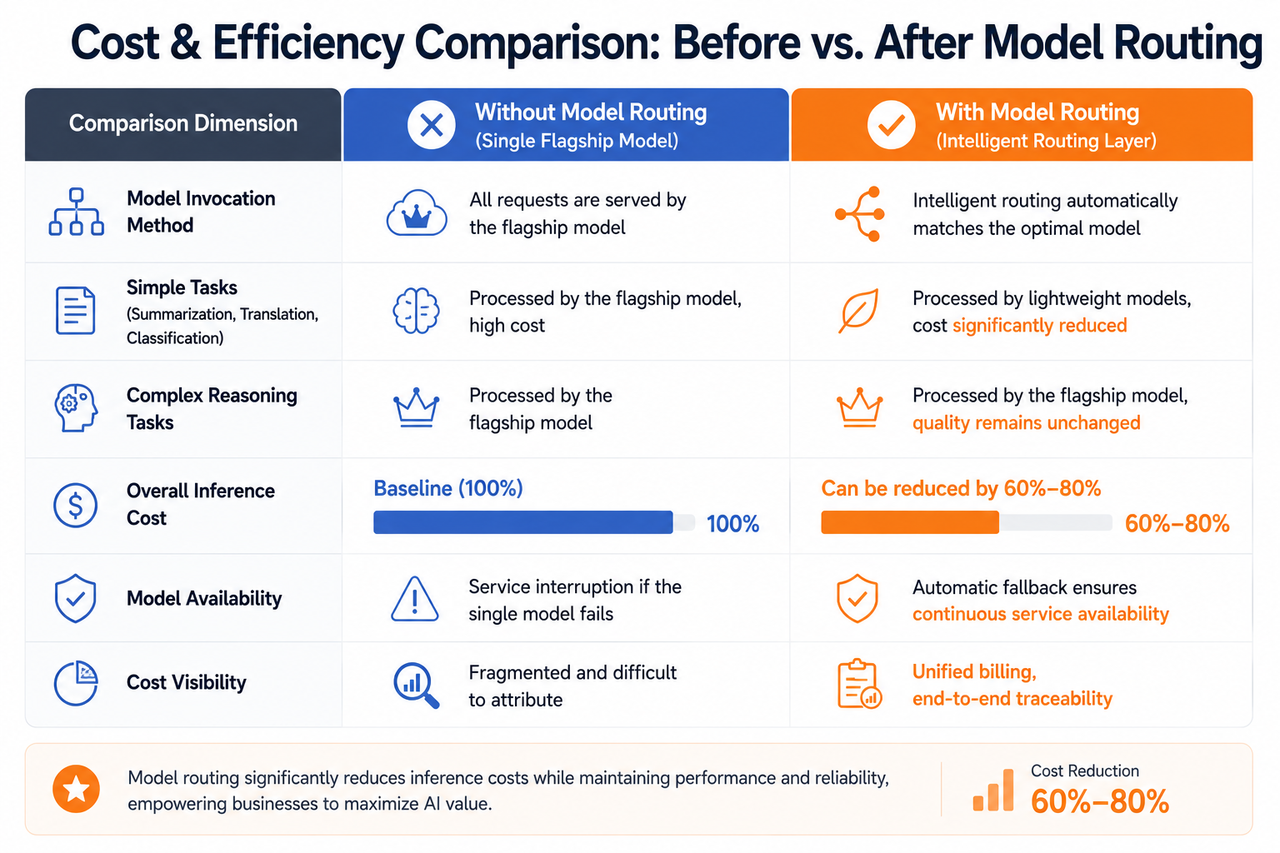
Comparing call costs and efficiency before and after model routing
Technical Architecture and Operation of the Model Routing Layer
The technical implementation of the model routing layer typically involves three core modules.
The request analysis module parses incoming requests, identifying task type, complexity, and priority. Some routing systems also assess features such as context length and required inference depth.
The routing decision engine is the heart of the model routing layer. Based on preset strategies—cost-first, performance-first, latency-first, or balanced mode—it selects the optimal target from the model pool. The decision engine must consider factors such as each model’s real-time load, response latency, current availability, and invocation cost.
The forwarding and failover module is responsible for forwarding requests to the selected model and automatically executing fallback switches if a model becomes unavailable or times out. This mechanism ensures high service availability—even if a particular model service fails, the routing layer can redirect requests to backup models, ensuring uninterrupted business operations.
Take Gate.AI’s automatic routing mechanism as an example. Developers don’t need to manually specify a particular model; by using model=auto in the request, the system automatically selects the most suitable model based on the task requirements. This shifts routing decisions from the developer to the infrastructure layer, dramatically reducing the complexity of multi-model integration.
Why the Model Routing Layer Is Becoming Essential Infrastructure
The model routing layer is evolving from an "optional component" to a "standard infrastructure element" for four key reasons.
Multi-model setups are now the enterprise default, not the exception. In 2026, enterprise AI is moving beyond reliance on a single major provider. Different models excel at different tasks—GPT series stands out in complex reasoning, Claude offers unique advantages in long-context understanding, and open-source models deliver better cost-effectiveness in specific verticals. No single model can cover all business scenarios. Multi-model collaboration has become the default architecture for enterprise AI.
Cost management is a non-negotiable requirement. As AI call volumes soar from millions to billions, model invocation costs have become a significant part of enterprise operating expenses. Organizations need clear visibility into every dollar spent on AI—which department is making calls, which model is most expensive, and which calls can be optimized. Only the routing layer’s unified measurement and analytics can provide these answers.
Data privacy and compliance requirements are stricter than ever. Enterprise data should not be used for model providers’ training or improvement plans. As an intermediary, the model routing layer can enforce zero data retention during request forwarding, eliminating the risk of sensitive data leakage at the source. For highly regulated industries like finance and healthcare, this capability has shifted from a "nice-to-have" to a "must-have."
Pressure to improve development efficiency. Integrating APIs from different providers, maintaining multiple SDKs, and handling diverse error codes and rate-limiting policies all contribute to technical debt. The model routing layer abstracts these differences behind a unified API, so development teams only need to learn a single integration standard to access all leading models worldwide.
Gate.AI in Practice: Unified Access, Intelligent Routing, and Enterprise Governance
Gate.AI exemplifies this trend—a single API covering over 200 mainstream models globally, including GPT, Gemini, Claude, Nemotron, DeepSeek, MiniMax, Qwen, MiMo, Kimi, GLM, ChatGLM, Grok, and more.
On the unified access front, Gate.AI supports both the OpenAI and Anthropic protocols, enabling migration without any need to refactor existing systems. Developers can integrate in just three steps: create an API Key, add Credits, and replace the Base URL and API Key. The platform is compatible with major development frameworks and tools such as LangChain, LangGraph, LlamaIndex, Cline, Cursor, Codex, and Claude Code.
On the intelligent routing front, Gate.AI’s built-in smart routing system automatically selects the right model resources based on task requirements, budget constraints, and performance goals. Routing decisions are dynamically scheduled using task characteristics, cost, and performance signals. If a model is unavailable or times out, the system automatically triggers a fallback switch to ensure continuous service availability.
On the enterprise governance front, Gate.AI provides unified billing and budget control, cross-model usage analysis, and cost attribution. Enterprises can establish multi-level organizational structures, manage API Keys at the team level, implement role-based access control, and enable end-to-end call tracking. The enterprise edition also supports SSO login and granular permission isolation.
On the data privacy front, Gate.AI does not store user input or output content by default and does not use any data for product improvement. The enterprise edition supports ZDR (Zero Data Retention) solutions and data processing agreements. Users can choose whether to enable log retention.
Gate.AI uses a pay-as-you-go billing model, with no fixed monthly fees or minimum spend. The platform’s prices are always in sync with official model pricing—there are no markups. Only successful calls that return results are billed; failed, timed-out, or automatically switched attempts incur no charges.
Conclusion
AI infrastructure is shifting from being "model-centric" to "routing-centric." The rise of the model routing layer is not just a theoretical concept—it is an architectural necessity emerging naturally as enterprise AI scales. When the number of models grows from single digits to double digits, when call volumes jump from millions to billions, and when costs become a measurable factor rather than a rounding error, a dedicated intermediary for unified access, intelligent scheduling, cost management, and data protection is no longer a luxury—it is essential infrastructure.
What Gate.AI offers is precisely this: a platform that integrates unified model access, intelligent routing, enterprise governance, and data privacy protection into a single solution. It is not a new model, but an infrastructure layer that enables better use of existing models. As AI applications enter the era of scale, one-stop model routing platforms are fast becoming the new choice for developers and organizations worldwide.


