From Fragmentation to Intelligent Routing: How Gate.AI Built a Unified API Platform for Over 200 Models
The AI industry in 2026 stands at an unprecedented turning point.
According to Gartner, global AI spending is projected to reach $2.59 trillion in 2026, up 47% year-over-year. Spending on AI models alone will soar from $15.5 billion in 2025 to $32.6 billion—a staggering 110% increase. Behind these numbers lies a structural shift: AI is moving from technical validation to large-scale deployment.
However, enterprises are quickly facing a new reality: the more models they use, the more challenges arise. APIs differ across vendors, billing rules vary, and key management systems are fragmented. Development teams must maintain separate integration code for each model, finance teams juggle multiple invoices, and operations teams constantly switch between dashboards. When a company uses an average of 4.7 models simultaneously—as was the industry average in Q1 2026—the hidden costs of fragmentation become impossible to ignore.
This is precisely the problem Gate.AI aims to solve: As the question shifts from "Do we have a model?" to "How do we use models effectively?", what enterprises need is not more models, but a unified AI infrastructure for centralized management, precise orchestration, and transparent governance.

From Single Model to Multi-Model Collaboration: Why Enterprises Must Rethink Their AI Architecture
Enterprise AI deployment in 2026 is undergoing a fundamental paradigm shift.
Over the past two years, AI has evolved from a productivity tool to a core element of digital transformation. Marketing teams use AI for content generation, R&D leverages AI for coding, customer service relies on AI for automated user support, and AI agents are now directly involved in business processes.
Yet as AI permeates more business scenarios, a key issue has emerged: performance varies significantly across different models and use cases. Code generation demands strong logical reasoning, long-form text processing relies on robust context retention, and multimodal understanding requires cross-modal alignment. No single model excels in all areas. Even the most acclaimed models show distinct strengths and weaknesses in real-world applications—some lead in long-document recall, others in low-latency multimodal interaction, and some offer superior throughput and cost-efficiency for high-concurrency tasks.
The focus of model selection has shifted from finding "the most powerful" model to identifying the best-fit model for each specific business scenario.
Industry data confirms this trend. Currently, about 69% of enterprises use three or more AI models in production, and the number of companies using six or more models has nearly doubled year-over-year. F5’s 2026 State of Application Strategy report further reveals that enterprises now rely on an average of seven AI models.
What enterprises need is not a single model, but a comprehensive infrastructure that enables flexible combination and dynamic orchestration of multiple models.
One API, 200+ Models: The Core Value of a Unified Access Layer
In the era of multi-model AI, the main challenge for developers isn’t model capability—it’s integration complexity.
Every model provider has its own API, authentication method, and billing rules. Integrating multiple models consumes vast amounts of time on interface maintenance, environment adaptation, and system migration. Gate.AI is designed to address this exact pain point—not as a new large language model, but as a unified access platform between applications and model providers.
Developers simply create an API Key in the Gate.AI console and replace the target endpoint in their existing application with Gate.AI’s unified entry point. This allows them to access over 200 leading models through a single API. The platform covers major global AI providers, including OpenAI, Anthropic, Google, Meta, xAI, DeepSeek, Alibaba, and Zhipu, among others. It offers both high-performance models for advanced inference and competitively priced lightweight models.
Crucially, Gate.AI natively supports mainstream API protocols, including the OpenAI API and Anthropic protocols. This means existing codebases built on these standards require no refactoring during migration and can be seamlessly integrated with popular development frameworks such as LangChain, LangGraph, LlamaIndex, Cursor, and Claude Code.
For developers, this unified approach delivers structural advantages: when testing new models, teams don’t need to redevelop entire interfaces; when business needs change, they can quickly switch model resources without modifying underlying architecture. For AI agents, automated workflows, and complex applications, unified access significantly reduces development and operational costs. Integration is as simple as three steps: generate an API Key in the console, top up Credits, and replace the Base URL and API Key.
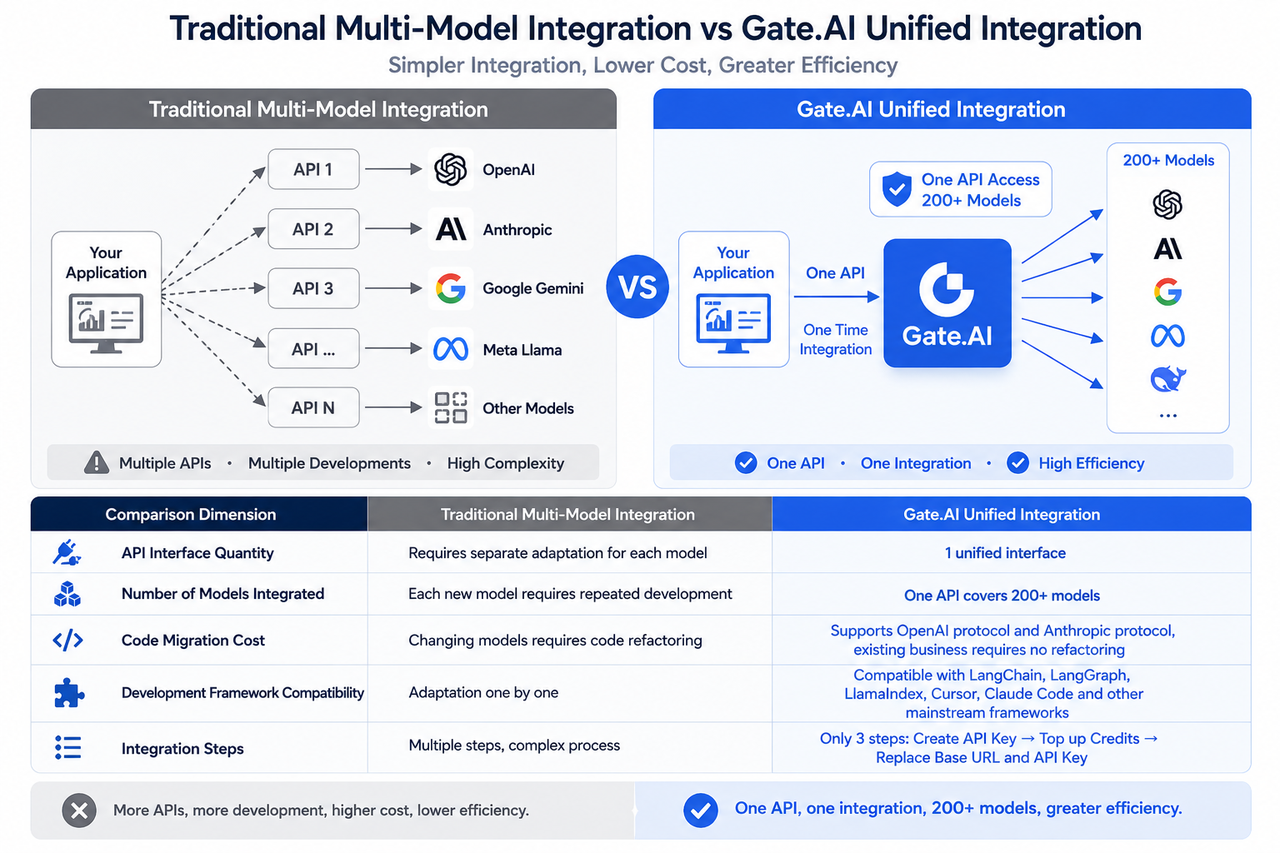
Traditional multi-model integration vs Gate.AI unified access workflow comparison
Intelligent Routing: Moving from Reactive Switching to Proactive Orchestration
If unified access solves the "Can we connect?" problem, intelligent routing answers "How do we choose the best option?"
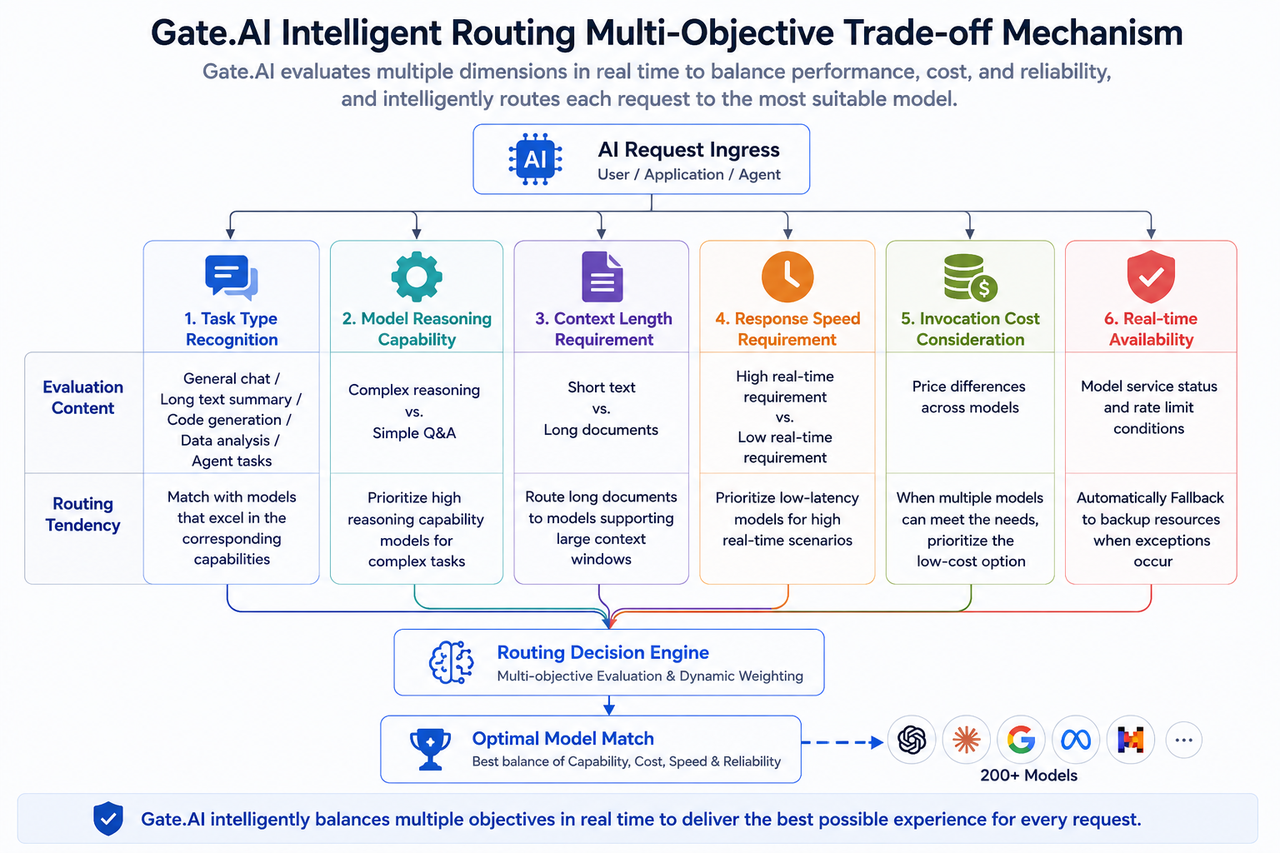
Gate.AI intelligent routing multi-objective optimization schematic
A common misconception in the industry is that model routing simply serves as a backup when the primary model is unavailable. In reality, Gate.AI’s intelligent routing is designed as a task-level dynamic orchestration system—not just a basic failover solution.
Processing an AI request involves several stages: request intake, task type recognition, model capability evaluation, routing decision, model execution, and result delivery.
Task recognition is the first step. The system determines the task type based on the request—whether it’s general conversation, long-form summarization, code generation, data analysis, or a tool-using agent task. Each type places different demands on inference capability, context length, and response speed.
Model capability matching comes next. The system references a model capability database to filter available models, evaluating dimensions such as inference power, context window size, response latency, tool integration, and multimodal support. Complex reasoning tasks are matched with models strong in inference, while long-document processing may be routed to models with large context windows.
Multi-objective optimization is the third phase. Routing decisions weigh multiple factors—model performance, response latency, invocation cost, and real-time availability—to generate the optimal route. When several models can accomplish the same task, the system may prioritize the lowest-cost option; for latency-sensitive business scenarios, low-latency models are given higher priority.
Additionally, the platform supports automatic fallback. If a model experiences throttling, service issues, or slowdowns, the system automatically switches to backup resources to prevent business disruption.
This intelligent orchestration not only enhances system stability but also helps enterprises significantly reduce AI costs. For AI agents and enterprise applications handling high request volumes, this capability is becoming increasingly critical.
Cost Governance: Making Every AI Expense Traceable and Optimizable
Another underestimated challenge in enterprise AI deployment is cost visibility.
Without a unified management platform, enterprises often can’t even answer the basic question: "Where is our AI spend going?" Different teams independently procure services, and departments integrate models separately, resulting in fragmented budgets, duplicated resources, and runaway costs.
Gate.AI provides unified billing and budget controls, cross-model usage analytics, and cost attribution, giving enterprises clear insight into every dollar spent on AI. The platform charges on a pay-as-you-go, prepaid credit basis, with no fixed monthly fees or minimum consumption requirements.
On pricing, Gate.AI mirrors official model pricing—what you see is what you pay, with no markup. For models that support caching, input tokens that hit the cache are billed at the official discounted cache rate. Only successful calls that return results are charged; failed, timed-out, or automatically switched attempts incur no fees.
The enterprise edition also supports custom volume discounts and annual contracts. Payment options include credit cards, Web3 wallet top-ups, and, for enterprise clients, large prepayments via fiat wire transfer or major stablecoins.
Data Privacy and Organizational Control: The Foundation of Enterprise AI Governance
Data security remains a core concern as enterprises adopt AI.
By default, Gate.AI employs a zero-data-retention policy: it does not store user input or output, nor does it use user data for model training or product improvement. Users can choose to enable log retention. The enterprise edition supports ZDR (Zero Data Retention) solutions to eliminate sensitive data leakage risks at the source. Enterprises that opt in to product improvement authorization can receive special request price discounts.
On the organizational management front, the platform supports team-level API Key management, role-based access control, and end-to-end call tracking. The enterprise edition offers SSO login, organizational structure management, and multi-level, role-based permissions for unified access and fine-grained segregation across teams and departments.
Conclusion
The AI industry in 2026 has entered a new era. While model capabilities continue to advance rapidly, the core challenge for enterprises has shifted from "Are models available?" to "How can we use models efficiently?"
Gate.AI is positioned at the heart of this challenge—as a unified gateway between applications and multiple AI model providers. With a single API, it connects you to over 200 models; with intelligent routing, it matches every task to the optimal model; with unified governance, it brings cost, permissions, and data privacy under centralized control.
As models move from competition to collaboration, Gate.AI is becoming the infrastructure gateway for enterprises entering the multi-model era.


