AI 基礎設施邁入第四層:Gate.AI 如何打造模型路由層
2026 年的 AI 產業正經歷一場深刻的典範轉移。業界討論的焦點已從「哪一個模型最好」轉向「如何讓多個模型協同運作」。根據產業數據顯示,2026 年全球 AI 總支出預計將達到 2.59 兆美元,年增長率達 47%,其中 AI 基礎設施支出將從 9,755.8 億美元躍升至 1.43 兆美元。全球科技企業在 AI 基礎設施上的資本支出總額已超過 6,000 億美元。
在這一波基礎設施擴張浪潮中,一個過去常被忽略的層級正逐漸浮現——模型路由層。它既不屬於模型訓練層,也不屬於推理服務層,而是作為 AI 基礎設施堆疊中的第四層獨立存在,承擔連結上層應用與下層模型資源的關鍵角色。

從三層到四層:AI 基礎設施堆疊的演進
傳統 AI 基礎設施通常被劃分為三個層級:運算層(GPU 叢集與算力資源)、儲存層(訓練資料與模型權重)以及模型服務層(模型訓練、微調與推理部署)。這一架構在單一模型主導的時代運作良好——企業只需串接 OpenAI 或 Anthropic 的 API,即可完成絕大多數 AI 任務。
然而 2026 年的市場格局已大不相同。沒有任何一個模型能在所有任務中保持絕對領先。生產環境同時運行五個以上模型已成常態。企業面臨的挑戰不再是「選哪個模型」,而是「如何讓多個模型在統一架構下協同運作」。
這一變化催生了 AI 基礎設施的第四層——模型路由層。它位於應用與模型供應商之間,承擔統一接入、智慧調度、成本治理與資料隱私保護等職能。模型路由層並不是新的大型語言模型,而是介於應用層與模型供應商之間的統一接入平台。
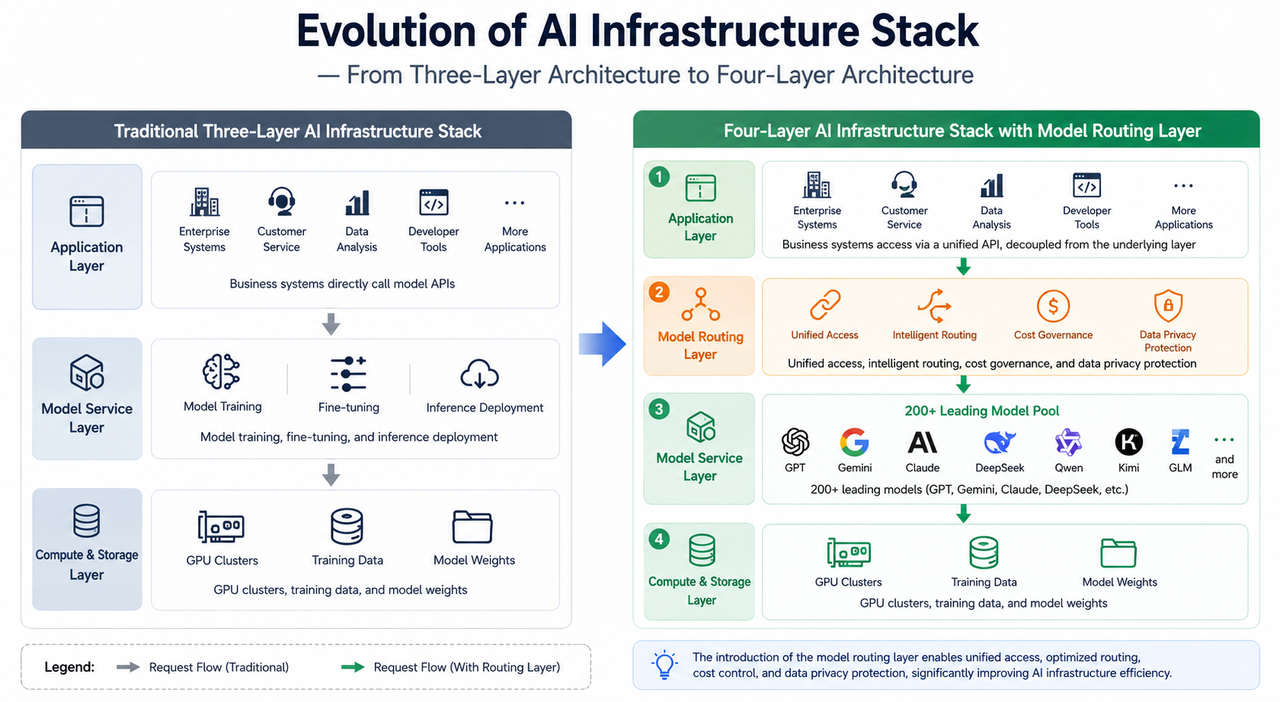
AI 基礎設施堆疊演進對比——從三層架構到四層架構
模型路由層:定義與核心價值
模型路由層是 AI 基礎設施堆疊中,負責將應用請求分配至最合適模型的智慧中介層。它在每次請求時評估任務特性,動態選擇最優模型,並將請求轉發至目標模型。
這一層與傳統的 API 閘道有本質差異。傳統 API 閘道擅長管理請求流量、執行身分驗證與速率限制;而模型路由層則需理解請求的內容特性——任務複雜度、所需推理能力、延遲要求與成本預算——並根據這些訊號做出路由決策。簡單來說,API 閘道關心「這個請求該不該放行」,模型路由層則關心「這個請求該交給哪個模型處理」。
模型路由層的核心價值體現在三個層面:
第一,解耦。 業務程式碼不再直接依賴特定模型供應商的 API。新模型上線時僅需在路由層完成設定,應用層無須任何更動。
第二,優化。 輕量級任務可使用低成本模型,複雜推理則交由高效能模型處理。有實務經驗顯示,智慧路由在特定場景下可將成本降低約 80%。
第三,治理。 統一統計調用量、延遲、失敗率與成本,實現全鏈路可觀測。
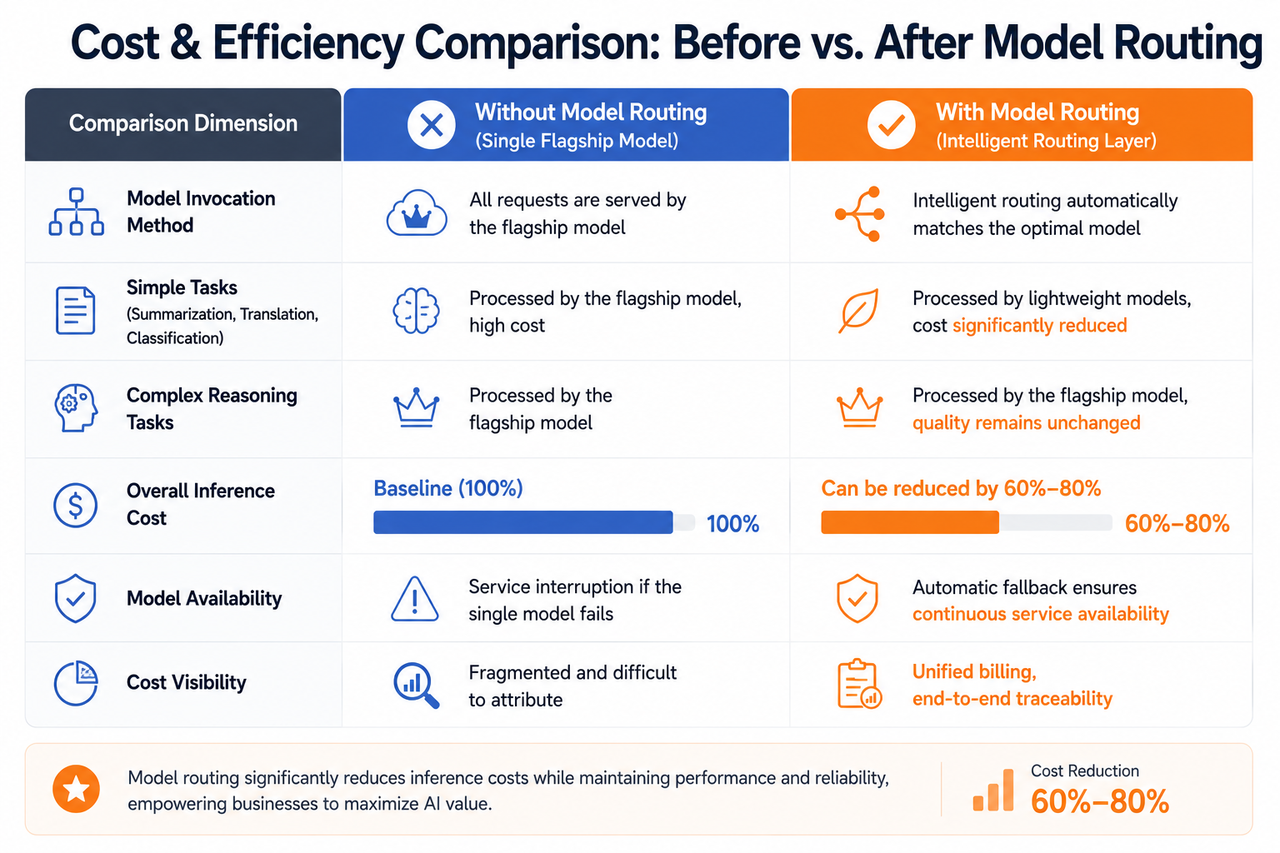
模型路由前後調用成本與效率對比
模型路由層的技術架構與運作機制
模型路由層的技術實現通常包含三個核心模組。
請求分析模組負責解析 incoming 請求,識別任務類型、複雜度與優先順序。部分路由系統還會評估請求的上下文長度、所需推理深度等特性。
路由決策引擎是模型路由層的核心。它根據預設策略——成本優先、效能優先、延遲優先或平衡模式——從模型池中選出最適目標。決策引擎需考量的因素包括各模型的即時負載、回應延遲、當前可用性以及調用成本。
轉發與容錯模組負責將請求轉發至選定模型,並在模型不可用或逾時時自動執行 Fallback 切換。此機制確保服務高可用性——即使某個模型服務發生異常,路由層仍可將請求導向備援模型,確保業務不中斷。
以 Gate.AI 的自動路由機制為例,開發者無需手動指定具體模型,只需在請求中使用 model=auto,系統即可依據任務需求自動選擇最適合的模型完成推理。此機制將路由決策從開發者手中轉移至基礎設施層,大幅降低多模型調用的複雜度。
為什麼模型路由層正成為新一代基礎設施
模型路由層從「可選組件」走向「基礎設施標配」,背後有四大驅動因素。
多模型成為企業標配而非選配。 2026 年,企業 AI 正逐步告別單一大廠依賴。不同模型在不同任務上各具優勢——GPT 系列於複雜推理表現突出,Claude 在長上下文理解上有獨特優勢,開源模型於特定垂直場域具備更高性價比。單一模型無法涵蓋所有業務場景,多模型協同已成企業 AI 的預設架構。
成本治理成為剛性需求。 隨著 AI 調用量從百萬級躍升至億級,模型調用成本已成為企業營運成本的重要組成。企業必須清楚掌握每一筆 AI 支出的流向——哪個部門在調用、哪個模型最昂貴、哪些調用可優化。這些問題僅能透過路由層的統一計量與分析能力獲得解答。
資料隱私與合規要求日益嚴格。 企業資料不應被模型供應商用於訓練或改進計畫。模型路由層作為中介,可於請求轉發過程中實施零資料留存策略,從源頭杜絕敏感資料外洩風險。對於金融、醫療等高度監管產業,此能力已從「加分項」轉為「入場門檻」。
開發效率的迫切需求。 分別串接不同供應商 API、維護多套 SDK、處理各異的錯誤碼與限流策略——這是一條技術債務之路。模型路由層透過統一 API 介面屏蔽底層差異,讓開發團隊僅需學習一套接入規範即可調用全球主流模型。
Gate.AI 的實踐:統一接入、智慧路由與企業治理
Gate.AI 是此趨勢下的典型實踐——一個 API 覆蓋全球 200+ 主流模型,涵蓋 GPT、Gemini、Claude、Nemotron、DeepSeek、MiniMax、Qwen、MiMo、Kimi、GLM、ChatGLM、Grok 等。
在統一接入層面,Gate.AI 支援 OpenAI 協議與 Anthropic 協議,現有業務無須重構即可完成遷移。開發者僅需三步即可完成接入:建立 API Key、儲值 Credits、替換 Base URL 與 API Key。平台相容 LangChain、LangGraph、LlamaIndex、Cline、Cursor、Codex、Claude Code 等主流開發框架與工具。
在智慧路由層面,Gate.AI 內建智慧路由系統,能根據任務需求、預算限制與效能目標,自動選擇合適的模型資源。路由決策依據任務特性、成本與效能訊號進行動態調度。當某模型不可用或回應逾時時,系統自動執行 Fallback 切換,確保服務持續可用。
在企業治理層面,Gate.AI 提供統一帳單與預算控管、跨模型用量分析與費用歸因。企業可建立多層級組織架構,實現團隊級 API Key 管理、基於角色的權限控管與全鏈路調用追蹤。企業版亦支援 SSO 登入與精細化權限隔離。
在資料隱私層面,Gate.AI 預設不儲存用戶的輸入與輸出內容,亦不將任何資料用於產品改進計畫。企業版支援 ZDR(零資料留存)方案與資料處理協議保障。用戶可自主選擇是否開啟日誌留存。
Gate.AI 採用按量計費模式,無固定月費及最低消費限制。平台與各模型官方價格同步,無任何加價。僅對最終成功返回結果的調用計費,失敗、逾時或被自動切換的無效嘗試均不產生費用。
結語
AI 基礎設施正從「模型中心」走向「路由中心」。模型路由層的崛起,並非單純的技術概念,而是企業 AI 規模化落地過程中自然浮現的架構需求。當模型數量從個位數變成兩位數,當調用量從百萬級成長至億級,當成本從可忽略變成可衡量——一個專責統一接入、智慧調度、成本治理與資料保護的中介層,已不再是錦上添花,而是基礎設施的必備組件。
Gate.AI 所提供的,正是一個將統一模型接入、智慧路由、企業治理與資料隱私保護整合於一身的平台。它不是一個新模型,而是一個讓現有模型能更好被運用的基礎設施層。隨著 AI 應用進入規模化時代,一站式模型路由平台正成為越來越多開發者與組織的新選擇。


